



La validation croisée est l’un des moyens les plus efficaces d’éviter le surapprentissage. Voir l’article : Comment savoir qu’une page n’est pas référencée ?. Contrairement à la validation classique, dans laquelle nous divisons les données en deux parties, dans la validation croisée, nous divisons les données d’apprentissage en plusieurs groupes.
Comment reconnaître le surapprentissage ? Si intuitivement votre modèle fonctionne très (trop !) bien avec les données d’apprentissage et, assez curieusement, ne parvient pas à faire un bon travail en production, il y a une forte probabilité qu’il s’agisse d’un problème de surapprentissage.
L’un des moyens les plus simples de lutter contre le surapprentissage consiste à diviser les données disponibles en deux ensembles distincts : un ensemble d’entraînement et un ensemble de test. Voir l’article : Quel est le rôle du SEO ?. Les échantillons utilisés pour tester les performances du modèle diffèrent alors de ceux utilisés pour l’entraîner.
Le sous-apprentissage se produit généralement lorsqu’il n’y a pas assez de données ou lorsque vous essayez de créer un modèle linéaire avec des données non linéaires. A voir aussi : Quelle information n’est pas indexée par les moteurs de recherche ?. En conséquence, le modèle est trop simple pour faire des prédictions correctes.

Le machine learning permet de tirer le meilleur parti du big data en identifiant des modèles et, grâce au data mining, en extrayant des informations exploitables et en identifiant des corrélations entre elles, des informations et des corrélations jusque-là inconnues.
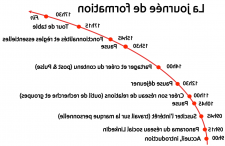
Quel est le principe du machine learning ? L’apprentissage automatique est une technique de programmation informatique qui utilise des probabilités statistiques pour donner aux ordinateurs la possibilité d’apprendre par eux-mêmes sans programmation explicite. … Pour apprendre, la machine doit consommer du big data.
Cas d’utilisation et applications. L’apprentissage automatique prend en charge de nombreux services modernes populaires. Un exemple sont les moteurs de recommandation de Netflix, YouTube, Amazon ou Spotify. Il en va de même pour les moteurs de recherche Web comme Google ou Baidu.
L’intelligence artificielle (IA) est un processus d’imitation de l’intelligence humaine qui repose sur la création et l’application d’algorithmes exécutés dans un environnement informatique dynamique. Son but est de permettre aux ordinateurs de penser et d’agir comme des humains.

Les algorithmes de construction d’arbres de classification sont généralement descendants et récursifs, chaque étape choisissant un prédicteur parmi les ps et une valeur de séparation de ce prédicteur qui divise « le mieux ». l’ensemble des observations en deux sous-ensembles de données.
Quels types d’algorithmes existe-t-il ? Graphique
Les algorithmes d’apprentissage automatique surveillés les plus importants sont : les forêts aléatoires, les arbres de décision, la méthode k-Nearest-Neighbor-Method (k-NN), la régression linéaire, la classification bayésienne naïve, la machine à vecteurs de support (SVM), la régression logistique et les gradients d’amplification.
Un logiciel d’exploration de données analyse les relations et les modèles de données transactionnelles stockées en fonction des demandes des utilisateurs. Il existe plusieurs types de logiciels d’analyse disponibles : statistiques, apprentissage automatique et réseaux de neurones.
La régression linéaire est l’un des algorithmes d’apprentissage supervisé les plus populaires. C’est aussi simple et parmi les mieux compris dans les statistiques et l’apprentissage automatique. La régression linéaire est un type de base d’analyse prédictive.

L’apprentissage en profondeur a permis la découverte d’exoplanètes et de nouveaux médicaments, ainsi que la détection de maladies et de particules subatomiques. Il élargit considérablement notre compréhension de la biologie, y compris la génomique, la protéomique, la métabolomique et l’immunomique.
Quelle est la différence entre le machine learning et le deep learning ? Alors que l’apprentissage automatique fonctionne à partir d’une base de données contrôlable, l’apprentissage en profondeur nécessite une quantité de données beaucoup plus importante. Le système doit avoir plus de 100 millions d’entrées afin de produire des résultats fiables.
L’apprentissage automatique est largement utilisé pour la science des données et l’analyse des données. Il permet de développer, tester et appliquer des algorithmes d’analyse prédictive à différents types de données pour prédire l’avenir.
La « profondeur » fait référence aux nombreuses couches que le réseau de neurones accumule au fil du temps pour améliorer ses performances au fur et à mesure de sa progression.
L’apprentissage profond utilise également l’apprentissage supervisé, mais l’architecture interne de la machine est différente : il s’agit d’un « réseau de neurones », une machine virtuelle composée de milliers d’unités (appelées neurones), dont chacune effectue de petits calculs simples.
Sources :




{kind=link}
{kind=link}